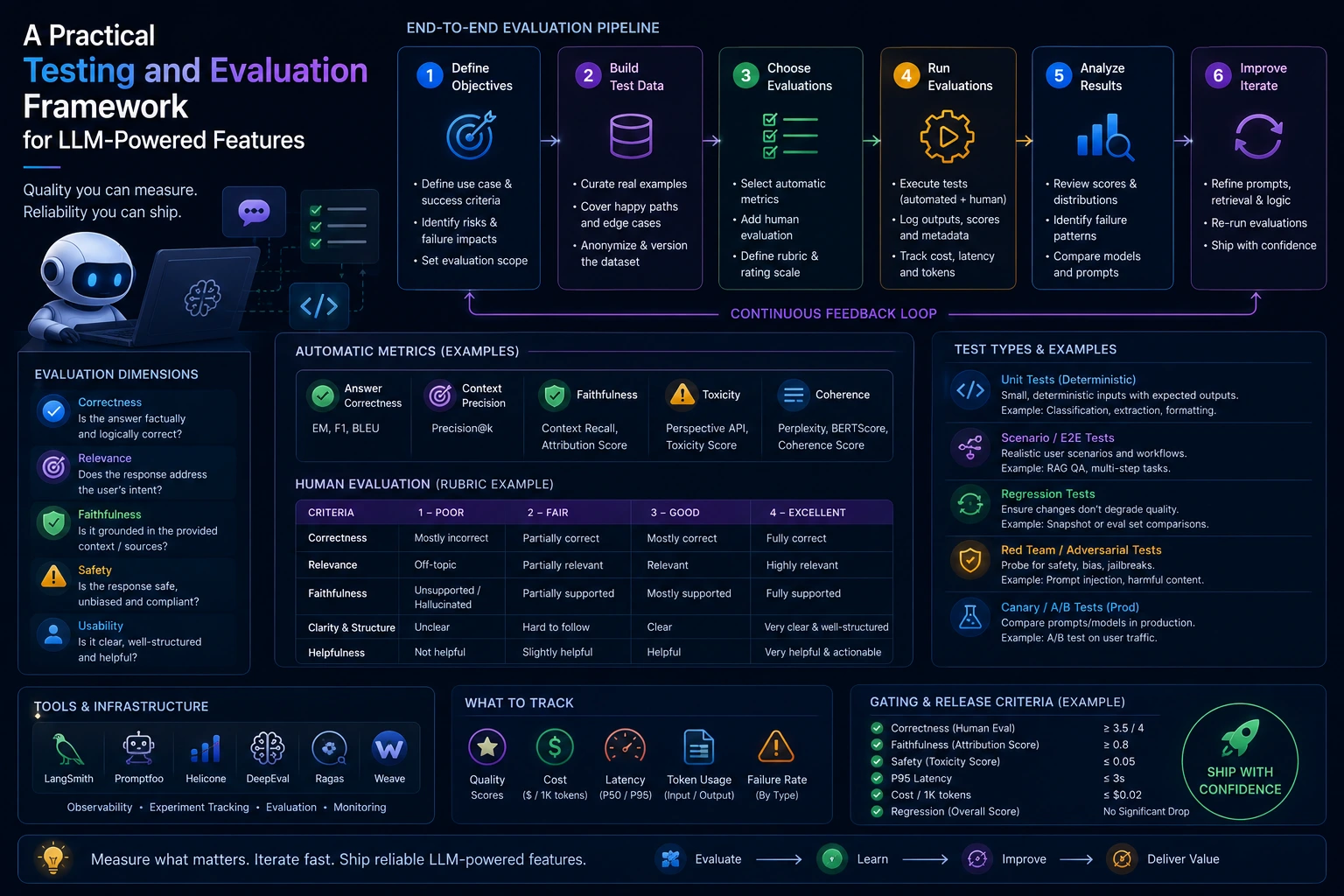
Testing LLMs is not the same as testing traditional software. Models are probabilistic, APIs change, and a single prompt can surface dozens of failure modes: hallucinations, prompt sensitivity, latency spikes, or regressions after a model swap. This post lays out a practical, repeatable framework for automated and semi-automated testing of LLM-powered features so teams can reduce regressions, measure quality over time, and safely ship changes.
What you should test (and why each dimension matters)
Start by deciding which dimensions of behavior matter for your product. Each one needs different tooling and acceptance criteria.
- Functional correctness: Does the feature do what the product promises? For an extractive summarizer that means required fields are present and formats match the contract.
- Factuality / hallucination: Is the model inventing facts? Measure using a labeled set where ground-truth can be verified automatically or by human raters.
- Safety and policy compliance: Detect toxic, biased, or disallowed outputs using classifiers and human review for edge cases.
- Robustness / adversarial input: Can the model handle malformed, ambiguous, or deliberately adversarial prompts?
- Style and tone: Does the output meet product requirements for brevity, formality, or domain-specific phrasing?
- Performance, latency, and cost: Track response time and token/compute cost as part of acceptance criteria for releases.
Core components of an LLM evaluation framework
A pragmatic LLM evaluation framework has five repeatable components: representative datasets, an evaluation harness, meaningful metrics and thresholds, CI integration, and a human-in-the-loop process for ambiguous failures.
Representative datasets
Use a combination of data types:
- Golden test set: Small, high-quality examples with definitive answers. Fast to run and ideal for pre-deploy gates.
- Holdout production samples: Real requests sampled from live traffic (anonymized) to keep tests relevant to user behavior.
- Synthetic and adversarial examples: Programmatically generated cases that probe known weaknesses (e.g., long context, ambiguous queries).
- Human-labeled evaluation batches: Periodic batches used to measure subtle qualities like helpfulness or nuance where automated checks are insufficient.
Evaluation harness and tooling
The harness runs prompts against a model, normalizes responses, computes metrics, and records results. Build it as a lightweight, idempotent service or test library that can be executed locally and in CI. Include tools for deterministic sampling, token normalization, and basic sanitization (strip timestamps, IDs) so comparisons are stable.
Metrics and thresholds
Pick a concise set of metrics your product team can act on. Examples:
- Exact-match / schema compliance (for structured outputs)
- Factuality score (human or classifier-based)
- Safety pass rate (automated blocklist + human audit)
- Average latency and p95 latency
- Regression delta vs baseline (absolute and relative)
Pair each metric with a clear threshold and the rollout policy if thresholds are breached (block release, require human review, or proceed with reduced traffic).
Designing tests that run in CI
Not every evaluation belongs in the fast pre-merge pipeline. Design a tiered testing strategy:
- Fast unit-like checks: Golden test set and schema checks that run on every commit. Keep this suite small (dozens of cases) and deterministic.
- Nightly/regression suite: Larger synthetic and holdout runs that exercise edge cases and cost more to evaluate.
- Pre-release gates: Full evaluation including human review and cost/latency benchmarks before model or prompt changes reach production.
To reduce flakiness in CI:
- Prefer deterministic model settings (fixed temperature or sampling seeds) for automated checks where supported.
- Normalize outputs before comparison (strip timestamps, canonicalize whitespace, collapse numeric formats).
- Use signal aggregation: require a statistical change across the suite rather than failing on a single example.
# Example CI job pseudocode
jobs:
run-llm-evals:
steps:
- checkout
- install-deps
- run: python tests/golden_tests.py --model $MODEL --fail-on-broken-schema
- run: python tests/synthetic_eval.py --model $MODEL --report results.json
- run: python scripts/assess_thresholds.py results.json --thresholds thresholds.ymlThe assessment script should return non-zero only when metric deltas exceed agreed thresholds; otherwise post results to a dashboard or artifact store for later analysis.
LLM regression tests and continuous monitoring
Regression testing for LLM features blends offline and online strategies:
- Baseline snapshots: Store baseline outputs and metric baselines for a stable model version. Use these to compute regression deltas after a model change or prompt update.
- Canary and shadow deployments: Run new models or prompt variants on a small percentage of live traffic (canary) or in shadow mode to compare outputs without affecting users.
- Automated drift detection: Continuously score sampled production responses against your holdout set distribution; alert on distribution shifts in content, length, or safety signals.
- Periodic human evaluation: Schedule weekly or monthly audits of random and flagged cases to catch subtle regressions automated checks miss.
Document what constitutes a regression: a meaningful drop in accuracy or an increase in safety violations that exceeds your tolerance. Tie alerts to an on-call runbook that specifies immediate steps (rollback, increase human review, throttle traffic).
Synthetic evaluation for LLMs: when it helps and when it hurts
Synthetic evaluation is useful to probe specific weaknesses quickly and at scale. Examples include paraphrase variants, prompt templates, or adversarial token insertions. But synthetic tests risk overfitting: models can be tuned to pass synthetic checks while failing real-world usage.
Use synthetic evaluation to augment—not replace—real holdout data and human labels. Treat synthetic examples as a way to expand coverage and exercise edge conditions, and periodically validate synthetic benchmarks against real-user performance.
Operational trade-offs and rules of thumb
- Start small: a compact golden set plus 100–500 holdout examples will catch many regressions early without high cost.
- Budget for periodic human review; automated classifiers won't find every hallucination or subtle stylistic failure.
- Invest in test data versioning. Tag test suites with model and prompt versions to reproduce failures later.
- Balance frequency: run fast checks on every commit, nightly suites for broader coverage, and full evaluations before releases.
- Measure cost per test run and factor that into your CI cadence: cheaper, high-value checks should be more frequent.
Reliable LLM testing relies on a small set of stable, well-understood checks for fast gating plus broader, costlier evaluations that run more slowly and include humans.
Practical checklist for shipping and maintaining LLM features
- Define success metrics and thresholds for your product (factuality, safety, latency).
- Assemble a golden test set and a holdout production sample; add synthetic adversarial cases for known risks.
- Implement a lightweight evaluation harness that normalizes outputs and computes metrics reproducibly.
- Integrate fast checks into CI and schedule nightly/regression runs for deeper coverage.
- Establish a canary deployment and shadow testing process to compare model variants on live traffic.
- Set up monitoring and alerts for metric drift, and document the rollback/runbook procedure for failures.
- Version test data and evaluation code; store evaluation artifacts and baselines for audits.
- Plan periodic human audits and calibrate automated classifiers against human labels.
When tests fail: a concise runbook
Have a repeatable, prioritized response to failures:
- Immediate triage: Is the failure transient (API outage) or persistent? Check system health and retry logs.
- Scope the regression: Compare failing examples against the baseline snapshot and determine whether the change affects broad traffic or a narrow slice.
- Mitigate: If severe, roll back to the previous model or route traffic away from the new variant. If medium, enable additional human review or reduce exposure.
- Root cause: Was the change a model update, prompt tweak, or infrastructure issue? Update tests or add new cases to prevent recurrence.
- Document: Record the incident, actions taken, and test-suite changes. Use this to refine thresholds and coverage.
Teams building LLM features will never reach perfect coverage, but a compact, well-instrumented testing and evaluation framework dramatically reduces surprise regressions and makes quality measurable over time. Practical testing combines automated CI checks, synthetic probes, regression suites, canaries, and human judgment in a predictable, repeatable pipeline.
Frequently Asked Questions
How do I start testing LLMs with limited resources?
Begin with a small golden test set (10–50 cases) that captures your product’s core behavior and a compact holdout of real requests. Add fast CI checks for schema and basic correctness, then schedule nightly runs for broader synthetic tests. Prioritize human review for high-risk failures.
What belongs in an LLM regression suite?
Include golden examples, domain-specific corner cases, adversarial inputs that previously caused failures, and representative holdout samples. Store baseline outputs to compute regression deltas after model or prompt changes.
How can I reduce flaky failures in CI when testing LLMs?
Use deterministic model settings where possible, normalize outputs before comparison, and aggregate signals rather than failing on single examples. Move expensive, non-deterministic checks to nightly jobs.
When should I use synthetic evaluation for LLMs?
Use synthetic evaluation to probe known weaknesses and increase coverage for edge cases, but validate synthetic benchmarks against real user data to avoid overfitting tests that don’t reflect production behavior.
How do I detect regressions after a model update?
Compare new outputs and metrics against stored baselines, run canary deployments or shadow tests on a subset of traffic, and set automated alerts for statistically significant drops in accuracy or increases in safety violations.
What are reasonable metrics to track over time for LLM features?
Track schema compliance, factuality or accuracy scores, safety pass rate, average and percentile latency, and cost per request. Pair each metric with clear thresholds and an action policy.