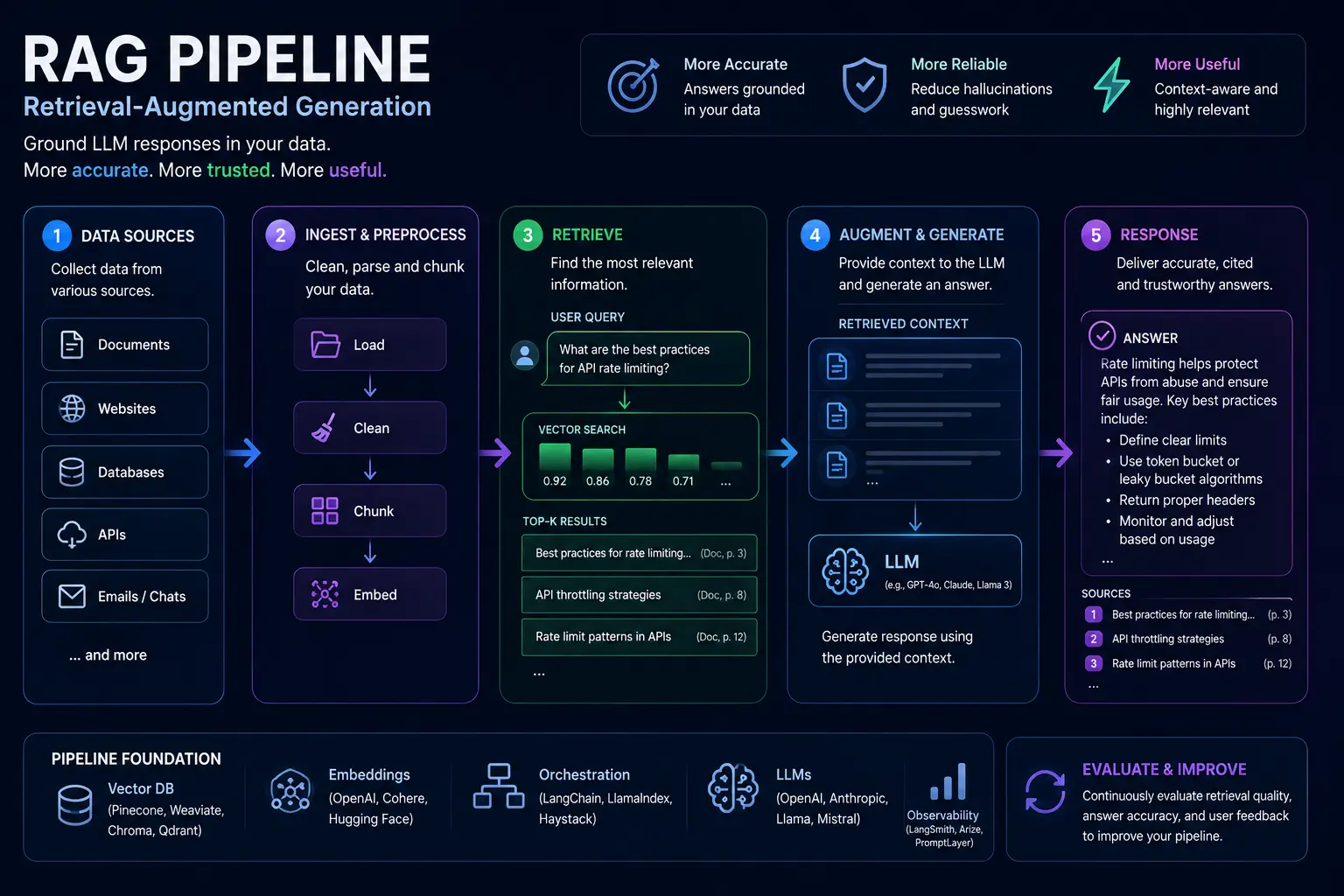
A production-ready retrieval augmented generation pipeline needs more than a working prototype: it demands reliable ingestion, consistent embeddings, tuned retrieval, sensible latency/accuracy trade-offs, and operational monitoring. This article gives a concise, practical checklist you can apply from raw documents to accurate, auditable answers.
How to use this checklist
Work through the sections in order: data and ingestion, preprocessing, embeddings and vector storage, retrieval tuning, prompt assembly and answer generation, then evaluation and operations. Each section lists concrete checks and the reason behind them so your team can prioritize work by risk and impact.
1. Document ingestion pipeline
Why it matters: Garbage in, garbage out. You must capture the right documents, preserve provenance, and standardize formats so downstream embeddings and retrieval produce reliable results.
- Inventory source systems and data owners. Know what content is authoritative and what is ephemeral.
- Normalize formats on ingest (text, HTML, PDF, images with OCR). Store both raw and parsed versions for traceability.
- Preserve metadata and provenance: source URL, fetch timestamp, author, revision id, and access controls.
- Implement incremental ingestion and deduplication. Avoid re-indexing unchanged documents to save cost and reduce drift.
- Add schema validation and alerting for parse failures.
2. Preprocessing and chunking
Why it matters: Chunk boundaries and context windows directly affect retrieval relevance and hallucination risk.
- Choose semantic-aware chunking, not just fixed bytes. Split on logical units (paragraphs, sections, headings) and keep small enough chunks to fit retrieval + prompt context.
- Attach neighboring context when a chunk is likely to be interpreted in isolation (e.g., table captions, figure text).
- Remove boilerplate and noisy content (navigation menus, repeated disclaimers) before embedding.
- Keep chunk metadata: original document id, position, and section header to enable precise citation in responses.
3. Embedding strategy
Why it matters: Embeddings are the foundation of semantic search. Consistency and versioning prevent retrieval drift and mismatches.
- Select a model that matches your content: short conversational text vs. long-form technical documents need different embedding characteristics.
- Standardize embedding dimensions and model version. Record the model and parameters with each vector to enable re-embedding decisions later.
- Decide on dense vs. hybrid retrieval (dense vectors + keyword signals). Hybrid strategies often improve hit rate for factual queries.
- Batch embeddings and handle rate limits; store both the vector and a human-readable text snippet for quick debugging.
- Plan re-embedding cadence: immediate for corrected content, scheduled for model upgrades or detected semantic drift.
4. Vector database selection and configuration
Why it matters: Your vector store shapes performance, cost, and operational complexity.
- Match capabilities to requirements: in-memory vs. disk-based, approximate nearest neighbor algorithms supported (HNSW, IVFPQ), and consistency guarantees.
- Test retrieval quality and latency with realistic query loads and data sizes. Don't rely only on vendor benchmarks.
- Evaluate persistence, backup, and multi-region replication needs for availability and compliance.
- Confirm metadata filtering and search-by-field support to enforce access controls and apply business filters at query time.
- Plan index maintenance: rebalancing, compaction, and periodic health checks to avoid performance degradation.
5. Retrieval tuning
Why it matters: The right retrieval settings maximize relevance while avoiding noisy context that causes hallucinations.
- Establish metrics: top-k recall for gold queries, precision@k, and mean reciprocal rank (MRR) when you have labeled data.
- Tune k (number of retrieved chunks) and score thresholds. More is not always better—irrelevant chunks can mislead the generator.
- Apply reranking: a lightweight cross-encoder or lexical reranker can reorder hits and sharply improve result quality.
- Use query expansion or paraphrase augmentation selectively for short or ambiguous queries.
- Monitor failure modes such as stale facts, topic drift, or over-reliance on a particular document source.
6. Prompt design and generation workflow
Why it matters: How you present retrieved context to the model determines answer accuracy and the ability to cite sources.
- Prefer explicit context windows: include retrieved snippets with clear delimiters and their provenance (document id, offset).
- Limit context size and prioritize relevance. Use a scoring scheme to pick the most informative, non-redundant snippets.
- Use instruction templates that constrain the model to cite sources, state uncertainty, and refuse to answer out-of-scope queries.
- Maintain modular prompt components (instruction, context, system message) so you can test variations without changing whole prompts.
- Test generation temperature and max tokens for each use case: lower temperature for factual answers, higher when creativity is required.
7. Answer accuracy, verification, and attribution
Why it matters: Users need correct, traceable answers. A RAG pipeline must help identify when the model is guessing.
- Implement citation-first answers: generate a short answer followed by explicit references to the retrieved chunks used.
- Run automated factual checks where possible (schema validation, numeric range checks, cross-checking against authoritative APIs).
- Surface provenance to end users and to downstream logs to support audits and corrections.
- Flag low-confidence answers and provide safe fallbacks: “I don’t know” responses, escalation to human review, or explicit uncertainty statements.
- Keep a corrections workflow so subject-matter experts can update source documents and trigger re-indexing or vector refreshes.
8. Evaluation and monitoring
Why it matters: Continuous measurement prevents silent degradation and guides improvements.
- Collect labeled query sets for regular regression tests covering common user intents and edge cases.
- Instrument production: record retrieved ids, prompt variants, model responses, latency, and user feedback signals.
- Track key metrics: answer accuracy (via human review), latency percentiles, cost per query, and incidence of hallucinations or refusals.
- Create alerting thresholds for sudden drops in relevance or spikes in latency.
- Run A/B tests for retrieval and prompt changes before full rollout.
9. Operational concerns: latency, cost, and scaling
Why it matters: Production constraints force trade-offs between speed, accuracy, and budget.
- Cache common queries and precompute embeddings for frequent documents to reduce repeated compute costs.
- Use a tiered model strategy: cheaper models for short answers or pre-checks, larger models for final generation when necessary.
- Profile end-to-end latency, not only model response time. Vector search, reranking, and network hops add up.
- Load-test retrieval and generation separately to identify bottlenecks and optimize autoscaling policies.
10. Data safety, privacy, and governance
Why it matters: Confidential or regulated data demands explicit controls to avoid leaks and maintain compliance.
- Classify content by sensitivity and enforce retrieval filters so restricted data is never surfaced to general queries.
- Ensure that embeddings and vector indexes comply with data residency and retention policies.
- Redact or token-mask personally identifiable information before embedding when required.
- Log access and maintain audit trails for queries that touch sensitive documents.
11. Maintenance checklist and versioning
Why it matters: Untended systems drift. A maintenance discipline keeps results predictable.
- Version embeddings, vector index schema, prompt templates, and model names in a central registry.
- Schedule periodic re-evaluation: retrain rerankers, re-embed content after major model updates, and prune old documents.
- Document rollback procedures for any model or prompt change that degrades quality.
- Keep runbooks for common incidents: slow searches, corrupted indexes, or unexpected hallucination spikes.
Practical example: retrieval + generation flow
# Pseudocode summary
query = user_input
emb_q = embed(query, model="emb-v1")
hits = vector_db.search(emb_q, k=8, filter={allowed_collections})
reranked = reranker.score(hits, query)
context = select_top_nonredundant(reranked, token_budget=1500)
prompt = build_prompt(system_instructions, context, query)
answer = llm.generate(prompt, model="gen-v1", temperature=0.0)
return {answer, citations: context.metadata}Where teams commonly trip up
- Not tracking provenance: when a user challenges an answer, you need to show the exact source fragment used.
- Overloading the prompt with noisy context, which increases hallucination risk instead of reducing it.
- Failing to measure real user queries and relying only on synthetic tests.
- Skipping versioning for embeddings and prompts; small changes can produce large, unexpected effects.
Small, repeatable checks (provenance, chunking, model/version metadata, and monitoring) buy more reliability than continual ad-hoc prompt tweaks.
Next steps
Turn this checklist into CI gates, monitoring dashboards, and a documented runbook. If you need a compact implementation guide, evaluate how your current stack matches each section above and prioritize fixes that reduce user-facing errors first: provenance, chunking, and retrieval tuning usually deliver the biggest improvements quickly.
Related internal reading
For a hands-on build example oriented to blog search, snippets, and citations, see the Wide Web Blog post titled "Build a Retrieval-Augmented Generation (RAG) Pipeline to Power Blog Search, Snippets, and Citations" which covers implementation patterns you can adapt to the checklist above.
Frequently Asked Questions
How do I choose a vector database for a production RAG pipeline?
Prioritize retrieval quality, latency, and operational features. Test with realistic data and queries for speed and relevance. Ensure metadata filtering, persistence, backups, and the ANN algorithms you need (HNSW, IVFPQ). Evaluate multi-region replication and the ease of index maintenance.
What chunk size should I use for documents?
Prefer semantic chunking by paragraph or section rather than fixed bytes. Aim for chunks that fit easily into your model context window with room for prompt instructions—typically a few hundred to ~1,000 tokens depending on the LLM and use case.
When should I re-embed content?
Re-embed after authoritative content updates, when changing embedding models, or on a scheduled cadence to correct detected semantic drift. For urgent corrections, re-embed the affected documents immediately and schedule a broader refresh.
How many retrieved chunks (k) should I pass to the generator?
Start small (3–8) and measure accuracy; incrementing k can improve recall but also raises hallucination risk. Use reranking and non-redundant selection to make each added chunk more likely to help than hurt.
How do I reduce hallucinations in RAG answers?
Limit context to high-quality, relevant snippets; use rerankers; require the model to cite sources; add verification checks; and flag low-confidence outputs for human review. Lower generation temperature for factual use cases.


